
Notes of CMU 11-711:advanced natrual language process
cmu高级自然语言处理
latest updating time:02:04:29 20 October 2025 UTC+8
0. before you read#
当下以大语言模型llm为主导的的nlp领域发展迅速,日新月异,笔者从课程安排来看,几乎每年都有变化,内容也会有所变动。所以这份笔记也许也应当具有时效性并随着时间推移进行迭代。但无论如何,姑且记录,作为个人学习梳理
1. Introduction to NLP#
nlp(natural language processing) 自然语言处理,研究如何让计算机理解人类语言的学科
1.1 自然语言处理问题总的的来说可以归结为如下几个问题#
- 处理分析语言(给一段话,理解这段话的内容,指出其情感等,文本分类)
- 人与机器交互(llm回答问题,生成代码)
- 协助人人交互(语法检查,翻译)
- 以及cv nlp结合 img和文本之间的转换
1.2 现在做nlp是要做什么#
为什么有些模型在有些方面表现得好(追求sota:state of the art )
为什么现在的sota模型在一些方面仍然有问题?
我们该如何改进我们的模型?
1.3 构建nlp系统的方法#
- 规则式构建模型(base on rules:如池袋,用一个固定的rule进行规范分类)不用经过训练
- 对没有训练的模型进行提示(大白话就是提示词工程!通过设计提示词,让llm在不再次训练的情况下达到我们的要求)
- 训练微调(微调:fine-tuning) 不只是llm,一些其他的基于训练的语言模型都是如此
1.4 动手构建最简单的规则式语言模型#
如:一个判定情感的model
五步走:
- 利用一个函数,提取特征(features)如:设定看到正向词语加一分,反之扣一分
- 算得分
- 构建决策函数,根据得分算出对应的结果
- 准确性分析:根据计算出来的结果和实际数据结果对比,测评准确性
- 根据准确性测评结果,进行误差分析并进一步修改
特征这个词语含义非常丰富,总之就是一种数学形式(一般我们用向量和矩阵),它可以承载着句子或者是词语的各种信息(在计算机视觉中,可能就变成了图像的信息),但是又经过了一定的处理和提取归纳,转化成可以发挥作用的形式。总之,他是机器学习中的一个关键元素,基本上代表了机器学习之后的成果,我们后续进行分类或是生成等等下游任务都要经过特征。
当我们重复这个循环之后,我们的模型在训练数据上面(train set)已经表现得准确度很高了,那么我们把它拿到测试数据上(test set)测评,再根据结果进行更改变化。是经典的 训练 测试 验证 逻辑。
然而规则式语言模型会有如下问题:
- 低频词难以处理
- 合成词难以处理(意思相近形态不同)
- 否定词对句子产生的影响难以处理
- 隐喻类比(整体句意无法处理)
- 其他语言无法处理
因而引出:nlp based on Machine Learning(基于机器学习的自然语言处理)
1.5 ML for NLP#
1.5.1 第一个尝试:词袋模型(basgs of words,BOW)#
每个词对应一个独热向量(one-hot vector),把句子中所有词向量加起来就是代表句子特征的向量, 乘以权重W
达到分类效果。通过ML,改进W矩阵
此处算法原理很朴素,每次训练结果对了词语的权重就加分反之减分,最后多轮训练可以通过最终输出的分数判断结果
1.5.2 BOW的缺陷#
- one-hot向量编码的问题:无法处理近义词和词语变形,词语数量一旦大了,词向量的长度会非常大,非常低效且浪费内存空间
- 无法处理but,否定等句意相关信息,对于词语位置没有感知力
1.5.3 改进:基于神经网络的模型#
- 通过复杂方法 把word编码成词向量
- 通过方法 把词向量提取为句子特征
- 根据神经网络处理句子特征
之后我们的研究其实都基于此,无论是transformer还是别的,本质上是对步骤一和二中方法 的改进,我们要找到一个可以提取语言特征的工具
2. Word Representation and Text Classifiers#
2.1 Subword Models(子词模型)#
2.1.1 SM原理#
为了改进one-hot向量,采用“字节对编码”(Byte Pair Encoding, BPE)
基本思路是统计句子中的字母组合出现次数 如:es er 然后将持续最多的组合记为一个子词,然后将子词作为整体,再持续循环,最终得到可以用来拆分词语的子词表,内容比如 :er est pro ed
于是可以处理词语变形,同时节省内存(可以用少量子词表示大量词语)
在获得子词表之后,我们以一元语言模型(Unigram LM,后面涉及)为例,来说明如何进行子词分割
通过一元语言模型,我们进行一些算法(这不太重要),最终通过ml获得一个 最优词汇表 可以通过它以及一些计算得到每个子词出现的概率
然后我们检查目标句子,进行不同的拆分方式,比如:est 拆成 e st 还是es t 最后选用概率最大的拆分方式就是结果
2.1.2 注意事项#
多语言方面,容易过度分割混合语言语料中的小语种
解决思路:对小语种进行采样
在如 es t和e st分割抉择上容易出问题
解决思路:通过“子词正则化”,在训练时对不同的分割结果进行采样以减少鲁棒性
2.2 Continuous Word Embeddings(连续词嵌入)#
对one—hot vector(独热向量)的大改进,使得用来表示各种词的向量长度大大减小,内存占用减少,同时具备了一些良好的性质,比如:“mom”-“female”和“dad”-“male”的词向量相似,近义词的词向量相似等
我们会得到一个词向量库,每次解码(将词转化为向量)只需要查找(look up)到相应向量即可
2.3 如何训练更加复杂的模型(ML基础回顾)#
不再赘述
2.4 Basic Idea of Neural Networks(for NLP Prediction Tasks)#
神经网络到底在干什么?
关键在于理解:提取并组合“特征”
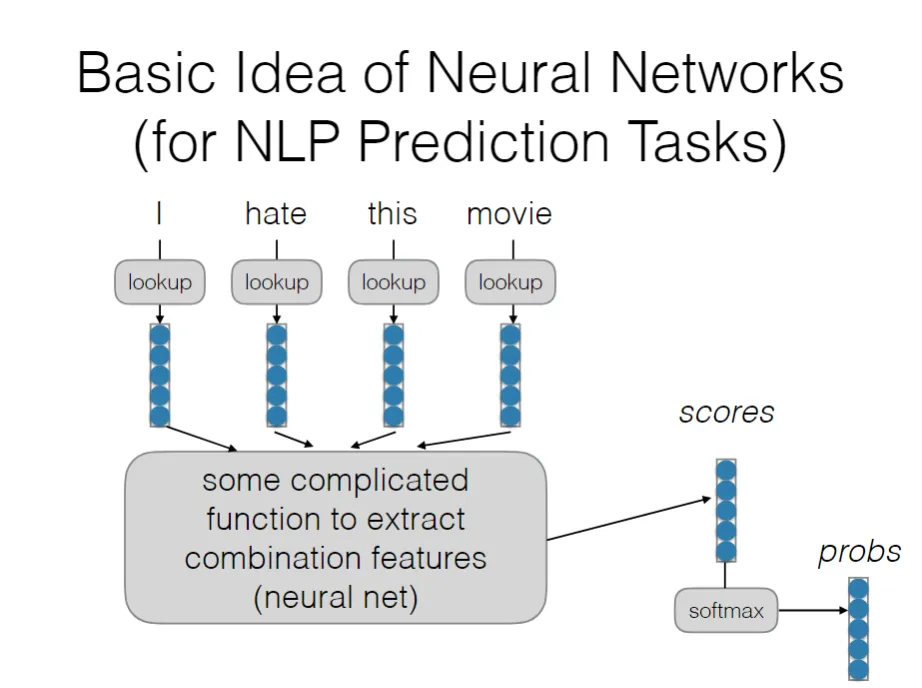
所有我们的基于深度学习的任务都可以归纳为利用各种神经网络架构去提取句子的特征(呈现为一个向量)(图中左侧部分)。这个向量包含了语言的features,也就是这句话的所有的信息,之后我们再通过神经网络提取出为了完成我们目标任务所需要的信息,并根据此即可完成任务(体现为得到scores,然后依据他来得到一个结果).
每一层的神经网络可以视为提取一个层次的特征,从低阶到高阶,第一层可能只是局部特征,比如词组结构,之后层数增加就可以在原有基础上提取更加抽象的特征,比如句子结构等关系。
特征有高阶有低阶,例如,每一个连续词向量的每一个维度都代表着一种特征,多轮学习之后的隐藏层向量的每个维度可能蕴含着特征,但是这种所谓特征并不是人为规定,而是经过ml之后自动学习出来的
3. Language and Sequence Modeling#
3.1 language models#
分为生成式语言模型与判别式语言模型,本质都是概率语言模型
~ (X是词语或句子)
生成式:预测下一个词
判别式:预测label的概率进行分类
3.2 Auto-regressive Language Models(自回归模型)#
:next token :context
那么我们的关键在于,如何找到计算的方式
3.2.1 Unigram Language Models(单元语言模型)#
core:最简单的语言模型,基本思想是,每一个词都与其他词独立,不会互相干扰
著名例子:信息检索tf-idf算法
3.2.2 小tricks:log参数化#
序列一大就会导致P(x)极其小,超出计算机能力范围。
于是通过取对数,把乘积问题转化为加法问题,之后处理梯度爆炸和梯度消失的时候也会运用对数参数化方法
3.2.3 n-gram Models(n元语言模型)#
在Unigram Language Models基础上加强了,认为 一个词出现的概率只与它前面固定数量的几个词有关
3.2.3.1 llm解释多元与单元语言模型的区别(参考资料) 单元语言模型和多元语言模型是两种不同类型的语言模型,它们在结构和工作方式上有显著区别。
单元语言模型(Unigram Language Model)
单元语言模型是一种最简单的语言模型。它假设句子中的每个词都是独立出现的,与其他词没有关联。换句话说,一个词出现的概率只取决于它自身在整个语料库中出现的频率。
特点: 独立性假设: 忽略词与词之间的顺序和上下文关系。 计算简单: 计算一个句子的概率时,只需将每个词的概率相乘即可。 局限性: 无法捕捉语言中的语义和语法结构,因为它不知道词语之间的联系。
举例: 假设我们有一个句子:“我 喜欢 吃 苹果”。 在一个单元语言模型中,它的概率计算方式是:
其中,、 等概率都是根据每个词在训练语料库中出现的频率来计算的。这种模型无法区分“我喜欢吃苹果”和“苹果喜欢吃我”这样的句子,因为它只关心每个词出现的概率,而不关心词语的排列顺序。
多元语言模型 (N-gram Language Model)
多元语言模型是单元语言模型的扩展。它假设一个词出现的概率只与它前面固定数量的几个词有关,这个数量就是“n”。常见的有多元语法模型(N-gram),其中n=2时称为二元语法(Bigram),n=3时称为三元语法(Trigram),以此类推。
特点:
- 上下文依赖: 考虑词语的顺序和上下文,能捕捉更丰富的语义信息。
- 计算复杂: 随着n的增加,需要计算和存储的概率数量会呈指数级增长。
- 更接近自然语言: 相比单元模型,它能更好地反映人类语言的语法和句法结构。
举例: 依然是句子:“我 喜欢 吃 苹果”。 在一个二元语法(2-gram模型中,它的概率计算方式是:
这里, 表示在“我”这个词出现之后,“喜欢”这个词出现的条件概率。这个模型考虑了前一个词对当前词的影响,所以它能更好地理解“我喜欢吃苹果”这个句子,因为它知道“我”后面出现“喜欢”的概率要比出现“苹果”的概率高得多。
随着n的增加,模型的表现会越来越好,但也面临“数据稀疏”问题,即很多n-gram组合在训练数据中可能从未出现过,导致概率为零。现代的大型语言模型(LLM)则超越了传统的N-gram模型,使用了更复杂的神经网络架构(如Transformer),能够处理更长的上下文和更复杂的语言依赖关系。
3.2.4 多元语言模型的问题#
- 近义词还是处理不了
- 间隔词处理不好 (intervening words):指的是在两个有强关联的词之间,存在其他不相关的词语。比如Mr.Perter Smith and Mr. Jane Smith,中间的词没有关系,但是产生较大影响
- n元规模不可能无限扩张,一般到7差不多了,所以对于长上下文依赖很难处理
3.2.5 优势#
那为什么我们还会用到他呢?
因为他相比神经网络类语言模型更加高效快速,在处理一些比较简单的语言任务中发挥更好的性能,对计算资源要求低。所以我们经常会用他来处理原始的上游数据,经过n元语言模型处理后的数据在用神经网络语言模型
3.2.6 基于神经网络的模型#
初期:特征化模型,为后来的高级模型提供铺垫。例子:前馈神经网络语言模型
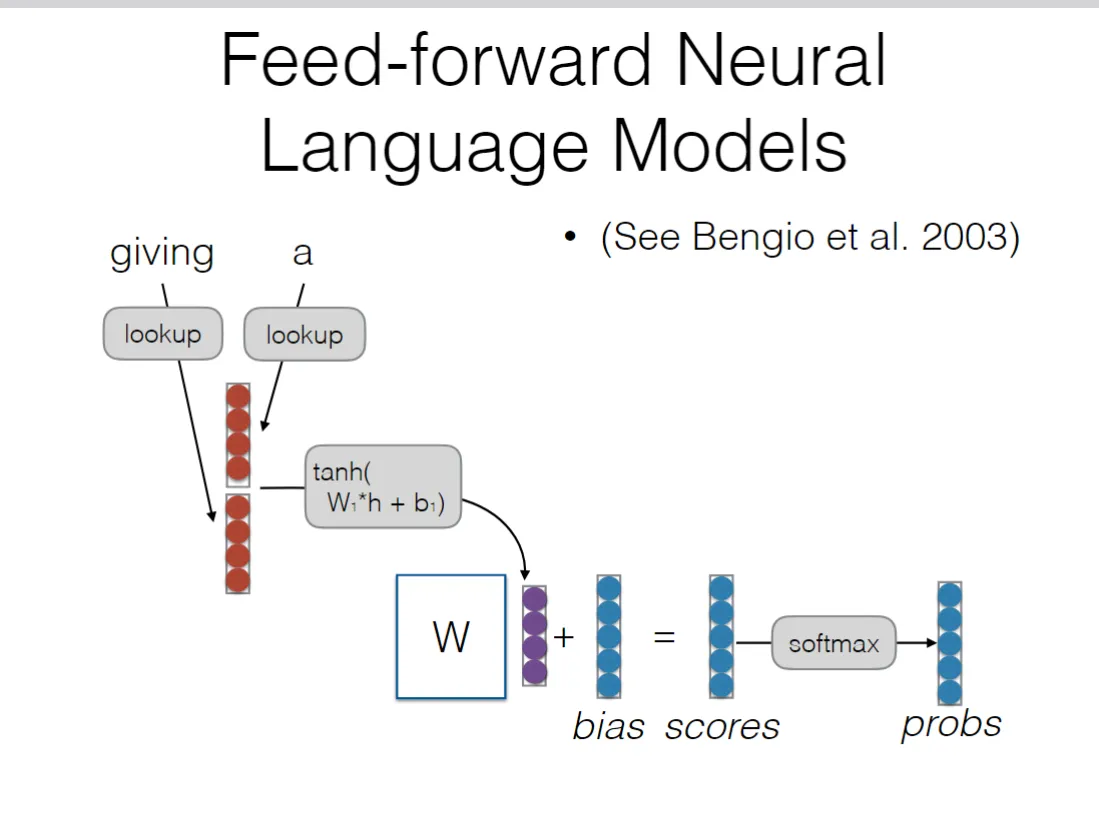
将词向量拼接成一个长向量,然后通过tanh激活函数和W1将其转化为低阶的隐藏层,在这个过程中W1的每一行都与行向量进行点积并加以偏置,获得了两个词向量的融合特征(原本的词向量,每个维度都代表着这个词的某一种特征),得到的新向量每一行都是新的融合特征,随后再来一次获得scores。这样,相似的词语有着相似的词向量,隐藏层也相似。进而可以处理同义词。而通过向量拼接并一起进行机器学习,可以将连续的几个词同时作为输入,也可以解决干预词的问题。但是由于拼接无可能无限长,而且必须认为预先定好数量,所以还是无法解决长距离语义依赖的问题
3.2.7 进阶:真正意义上成熟的序列模型#
- RNN(循环神经网络)&LSTM(Long short time memory)
- CNN(卷积神经网络)
- attention
3.2.7.1 RNN:#
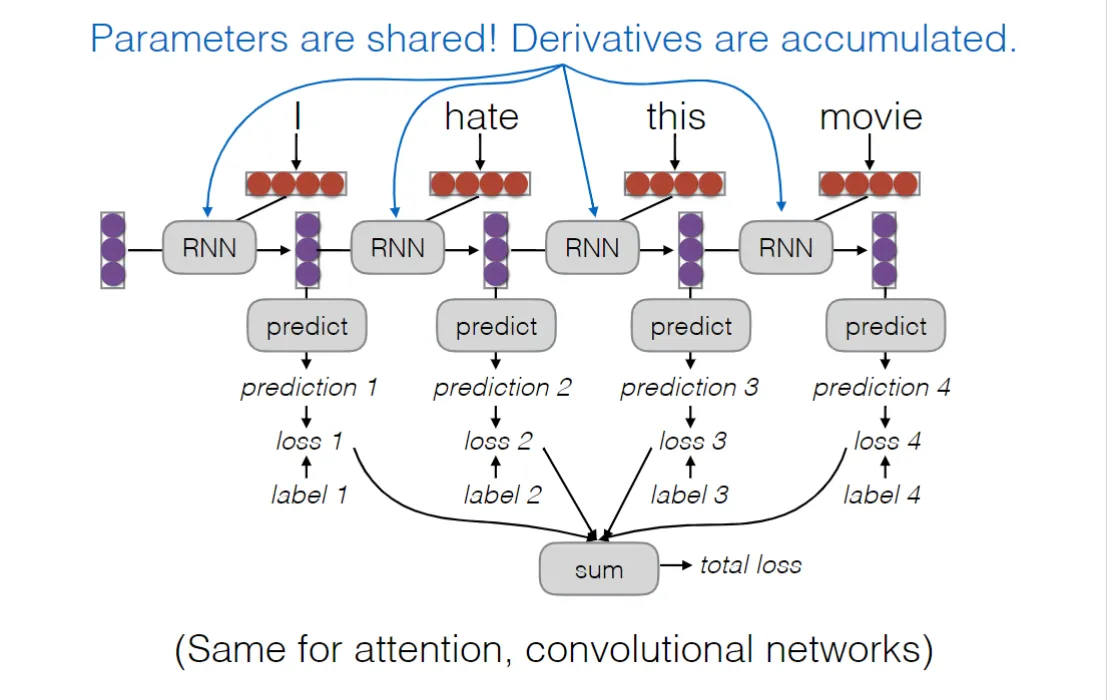
模型之类的不再赘述,关于反向传播倒有些新意:三个中间参数W,在各个时间步中保持一致,一次更新全部更新
双向RNN:单项rnn智能让模型利用前面的信息,双向rnn让模型可以兼顾前面的信息和后面的语义信息,因为前后文对理解一个句子之中的词义都有帮助(有点像掩码模型的思路)
RNN的缺陷:梯度爆炸。
推导
for the k step:
递归展开后,梯度项会不断乘以 ,最终公式为:
当 时, 随 增大呈指数级增长(梯度爆炸);当 时, 随 增大呈指数级减小(梯度消失)。
3.2.7.2 LSTM:#
在RNN的基础上,提出了LSTM进行改进
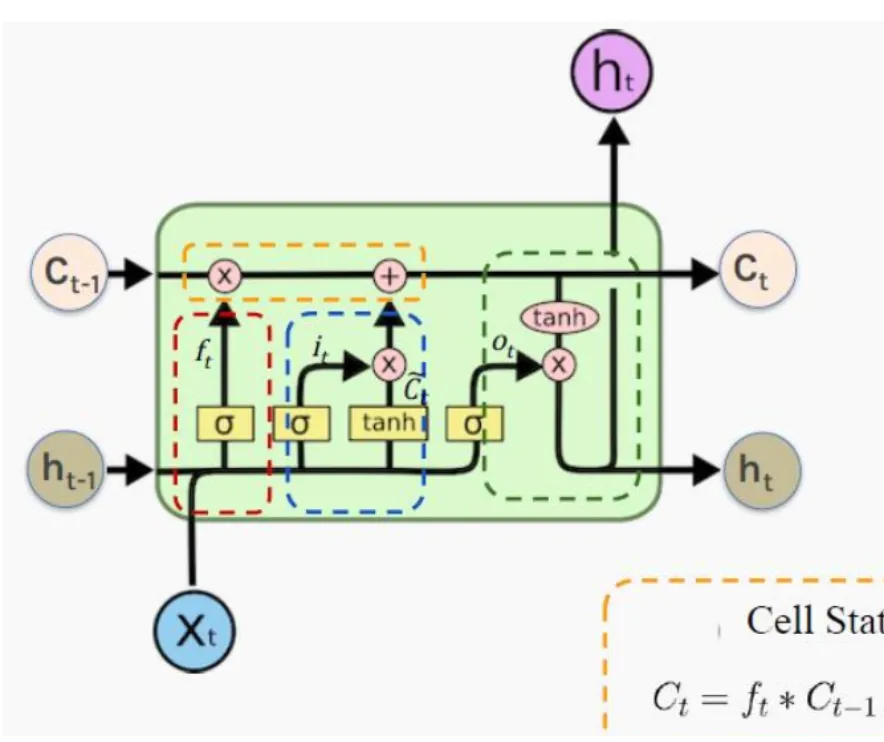
is the input vector
is the hidden state like RNN
is the cell state,which can store information for long periods of time(like memory)
有三个“门”:遗忘门,输入门,输出门
遗忘门:进来之后,和相乘
值得指出的是, (sigmoid)函数的性质导致了向量上的数值在0~1,于是这个向量中的每一个元素都代表了一个遗忘因子:如果某个元素的值接近 1,这意味着对应的旧信息(细胞状态中的一个维度)应该被完全保留,或者说,几乎不被遗忘。相反,如果某个元素的值接近 0,这意味着对应的旧信息应该被完全遗忘,或者说,被丢弃。
遗忘门其实是LSTM和RNN最大区别之一,通过这种遗忘的机制,有效保留了重要的信息忽略了长期记忆中需要丢弃的信息,从而使得长期记忆成为可能
输入门:也就是把现在的输入和之前的隐藏状态结合起来,经过一个sigmoid函数,得到一个0~1之间的向量,这个向量决定了当前输入的信息中哪些部分是重要的,应该被写入到细胞状态中。然后通过一个tanh函数,将和结合起来,得到一个新的候选值,这个候选值包含了当前输入的信息。最后,将和相乘,得到当前输入中应该被写入细胞状态的信息。 然后将这个信息加到用遗忘门更新后的细胞状态中,更新完毕:
输出门:取舍新的细胞状态(记忆)中的信息,我们得到了输出
LSTM的优势在于缓解了RNN的梯度消失问题,使得模型能够更好地捕捉长期依赖关系。
如何实现?我们看到:
进行梯度回传
我们来看看这些复杂项的链式法则展开:
这些项都涉及到了隐藏状态对细胞状态的导数 。而 ,这个导数包含输出门 和 tanh 的导数 。这两个项的元素值都小于1。因此,这些间接路径上的梯度在回传过程中会不断乘以小于1的值,导致其指数级地衰减。随着时间步的增加,这些间接路径的梯度贡献会迅速变得微不足道,于是:
由于我们处理的上下文肯定是有逻辑的,(如果上下文非常无关的话,遗忘门中的元素会频繁出现趋近于0,但是这种文本数据价值本身就很低)所以遗忘门中的元素大多趋近于1(大多数的的信息还是会被保留下来),于是防止了梯度爆炸 (函数结果在0~1之间),同时减缓了梯度消失
3.2.7.3 CNN:#
CNN在语言处理中很简单,就是简单的设定滑动窗口大小然后逐一采集特征:
如果是自回归模型进行语言生成的话,就改成:
CNN的用途:可以提取出几个连着的token的特征,这样可以提取出词组的信息,可以构建出文字组合的联系,但是还是无法解决长距离依赖的问题,而且各个词的位置信息还是没能体现
3.2.8 模型的效率评估和提升tricks#
指标:
参数量(Parameter count): 指的是模型中可训练的参数总数。参数量越少,模型通常越小,需要的内存和计算资源也越少,但模型的表达能力可能受限。
内存使用(Memory usage,主要看峰值): 指的是模型运行时占用的内存大小,包括模型本身以及在推理(或训练)过程中所需的临时内存。
延迟(生成第一个token,到最后一个token所花的时间)
吞吐量(Throughput): 指的是在单位时间内模型能处理的请求(或数据)总量。吞吐量越高,说明模型在处理批量任务时越高效,能够更好地服务多个并发用户。
蒸馏/压缩(distillation/compression)”和“生成算法(generation algorithms)都是为了提高模型的效率和性能而提出的技术手段。
3.2.8.1 mini-batching#
由于现代计算硬件在处理矩阵问题方面GPU比CPU更好,例如对于10个数据,一次性处理10个数据要比10次处理每个数据要快,因此可以通过将多个样本组合成一个小批量(mini-batch)来提高训练效率。小批量训练可以充分利用GPU的并行计算能力,从而加速模型的训练过程。在训练过程中常用地方法是进行concatentate(进行矩阵拼接),然后将最后每个并行结果加和汇总
3.2.8.2 其他优化tricks#
1.不要把同样操作放入循环内,不如提前算好
2.循环可以用拼接代替
3.减少CPU和GPU之间的数据移动,最好一次性完成
4. Attention and Transformer Models#
4.1 attention#
4.1.1 attention基本思想#
query(查询向量),key(键向量)
语言序列中地每个token对应一个key向量,通过将q和k建立关联,得到注意力分数,
注意力分数通过softmax函数进行归一化处理,得到每个token在当前上下文中的重要性权重。
例如:假设你正在使用一个模型来生成一张图片的文字描述(Image >Captioning)。
输入:
序列A (查询 Query): 待生成的文字描述(例如,一个不完整的句子,比如“一只>猫…”)
序列B (键 Key 和值 Value): 一张照片的视觉特征向量(例如,通过卷积神经网络从图片中提取的一系列特征,每个特征向量代表图片中的一个区域,比如猫的耳朵、眼睛、背景等等)。
其中K Q V的计算均通过,,进行机器学习得到工作流程: 当模型想要生成下一个单词时,它会进行以下操作:
查询(Query): 模型会使用当前已生成的文字信息(例如,“一只猫”的向量表示)来生成一个查询向量。
键(Key)与值(Value): 同时,图片中的每一个视觉特征向量(比如猫的眼睛、嘴巴、尾巴等)都扮演着键和值的角色。
计算注意力权重: 模型将查询向量(代表“一只猫”)与图片中所有的键向量(代表眼睛、嘴巴、尾巴等)进行比较。 它会发现,“一只猫”这个查询与猫的眼睛、胡须和尾巴这些区域的键向量最相似。因此,这些区域会得到最高的注意力分数。
加权求和,生成上下文向量: 这些注意力分数被转换为权重后,模型用这些权重对所有视觉特征向量的值(v)进行加权求和。最终,模型会得到一个上下文向量。 这个上下文向量集中了图片中最相关的视觉信息,也就是猫的眼睛、胡须和尾巴的特征。
生成下一个词: 模型将这个上下文向量与已生成的文字信息结合起来,预测下一个最有可能的单词是“在”或“躺在”。
4.1.2 self-attention and cross-attention#
上述例子就是一个基本的cross—attention的例子,一个语言序列中的词向量作为q,另一个序列中的词向量作为k,对于第一个序列中的tokens,我们找到在第二序列中各tokens对应的注意力分数,也就是最相关的信息点。常用于处理不同信息转换,经常用于机器翻译,以及多模态转换(比如图像信息转为文字信息)。
而self-attention,就是始终以同一个序列作为对象,kq均从同一个序列中产生,于是我们最后得到的注意力分数描述的是对每一个token他在本身在一个句子中的地位以及相关的其他信息。现代大语言模型比如gpt系列都在用自注意力机制
将所有的这些每一个token得到的注意力分数进行汇总,就可以得到整个句子的信息,也就是上下文向量。
4.1.3 Attention Score Functions#
我们前面只说了kq之间可以建立关系得到注意力分数,但是具体的计算方法有多种。
- Multi-layer Perceptron(MLP)
Flexible, often very good with large data(flexible:运用了非线性的tanh使得学习能力更强) - Bilinear(双线性函数)
More efficient than MLP, but less flexible() - Dot Product
No parameters! But requires sizes to be the same. - Scaled Dot Product
Problem: scale of dot product increases as dimensions get larger Fix: scale by size of the vector
4.1.4 Masking for Training#
这是一种对训练数据的处理方法

在我们给模型投喂训练数据的时候,如果投喂整个句子的话,那么前后文都都会被看到,那就达不到我们想要的,希望模型能够通过预测未来词语来进行学习进步的效果(相当于抄答案了)。但是我们也希望:在训练模型(比如 Transformer)时,我们能通过一次性进行大规模的矩阵乘法来提高效率,而不是一个词一个词地循环处理。
于是如图中所展示,我们把后面的词通过掩码(masking)把他们遮住(对应方法应该是用极小负数填充),然后将每个掩码的句子合并为一个大矩阵进行训练
4.2 transformer#
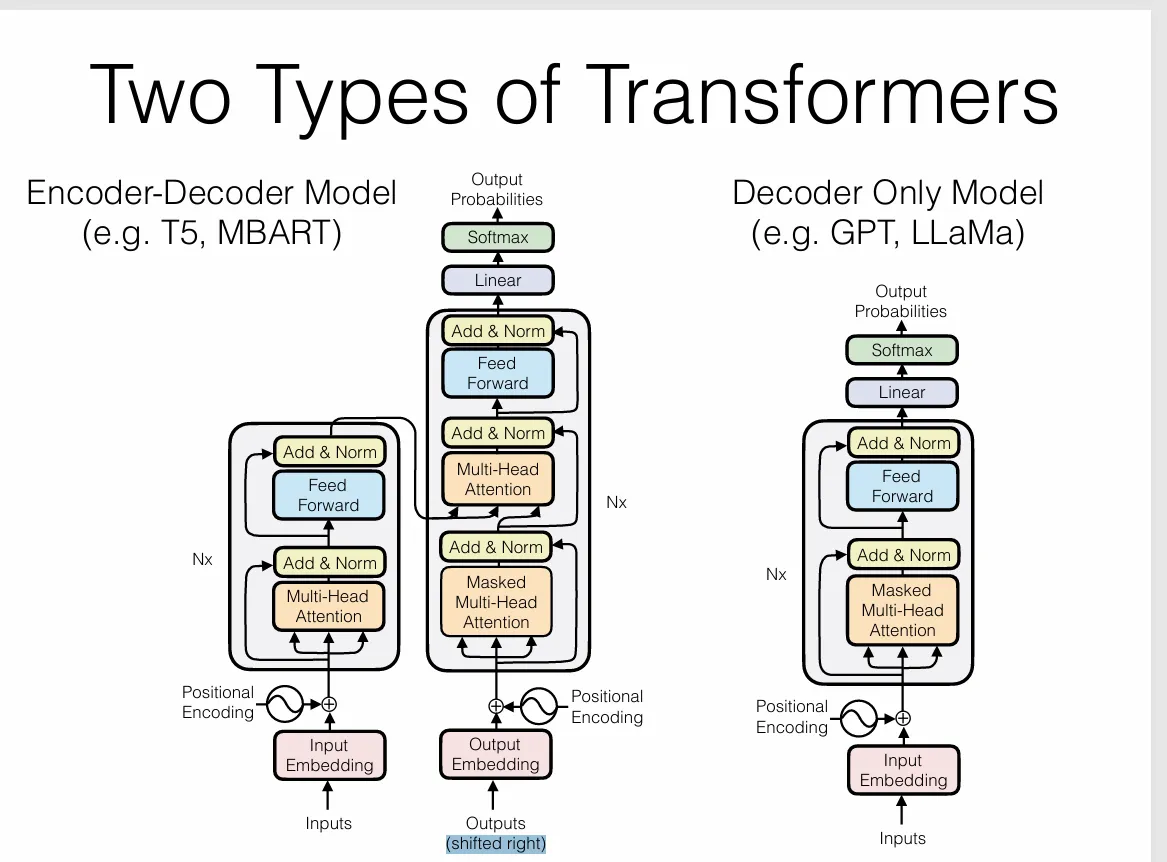 理解transformer的关键就是理解这幅图。
理解transformer的关键就是理解这幅图。
首先我们看到两种类型的transformer:Encoder-Decoder Model (左)和 Decoder-Only Model(右)。
区别在于,左边的模型同时使用了编码器和解码器,先将输入语句进行向量化,再将再将其编码变成包含了句意信息的上下文向量,然后加入中间的多头注意力进行交叉注意力机制处理。于是这个上下文向量就变成了后续文本生成的极大依赖(由他产生k,v),q由下面的outputs向量产生。最开始给的是一个特殊的起始符向量(shifted right:将输入序列向右移动一个位置,并在序列的开头添加一个特殊的起始符,比如
由于这种方式对于编码器处理的input向量极度依赖,,所以常用于机器翻译等需要严格按照输入规则来的任务。
右边是纯解码器模型(Decoder-Only Model),它只使用了解码器部分。输入是一个已经存在的文本序列,目标是生成下一个最有可能的词。解码器通过自注意力机制来关注输入序列中的所有词,并生成下一个词的概率分布。由于不需要编码器的上下文信息,这种模型在处理生成任务时更加灵活。同时由于注意力机制只依赖于本身生成的内容,更加适合处理文本生成等规则更少更灵活的任务。
我们就用现在的大语言模型来举例子,同样是输入prompt。Encoder-Decoder Model会将prompt进行编码,得到一个上下文向量,然后依赖上下文向量通过交叉注意力机制来生成后续文本。而Decoder-Only Model则直接使用prompt作为输入,将其视为之后生成内容的一部分,通过自注意力机制来生成下一个token。
4.2.1 how transformer work(details)#
Core Transformer Concepts:
- Positional encodings(位置编码)
- Multi-headed attention(多头注意力)
- Masked attention(掩码注意力)
- Residual + layer normalization(残差连接&层归一化)
- Feed-forward layer(前馈层)
两种transformer本质一样,我们以全解码模型为例展开分析。
-
首先进行word embedding,也就是之前讲过的词向量化操作,可以运用之前的知识(2.2节),不再赘述
-
进行位置编码(positional encoding)。(解释清楚位置编码需涉及到多头注意力机制的原理,可以先往后看) 由于注意力机制对每个词向量进行kqv的查询,我们会发现对于一个同样的词,在transformer中是排列不变性 的,这意味着如果打乱一个句子中词语的顺序,自注意力机制的结果是完全一样的,但是实际上,两者的意思肯定会有差别。这显然不符合语言的特性,因为词语的顺序非常重要。
比如说两个“big”在不同上下文中的含义可能完全不同,一个可能是修饰“big cat”,另一个可能是“修饰big data”,这就需要位置编码来帮助模型区分。
所以我们会在词向量化的时候在原有矩阵的基础上加一个包含位置信息的矩阵,最终得到的词向量为。位置编码的方式有两种,一种是学习式的位置编码,就是将位置编码矩阵作为一个可训练的参数矩阵,和词向量矩阵一起进行机器学习。另一种是固定式的位置编码,就是通过一些数学函数来生成位置编码矩阵,比如说正余弦函数:
其中是词在句子中的位置,是词向量的维度索引,是词向量的总维度。这样,每个位置都会有一个独特的编码,这个编码会随着位置的变化而变化,从而帮助模型区分不同位置的词。
这种正余弦函数的位置编码方式有一个好处,就是它可以让模型更好地捕捉到词之间的相对位置关系,因为正余弦函数具有周期性,可以表示不同位置之间的距离关系。还有一种更为重要的分类:绝对位置编码和相对位置编码:
绝对位置编码:最常见的方法是向词向量中直接添加一个表示其绝对位置的向量。但这有两个缺点:一是模型无法自然地理解词语间的相对距离;二是它无法泛化到比训练时更长的序列,因为模型没有见过这些位置编码。
相对位置编码 (Relative Positional Encoding):另一些方法尝试直接在自注意力机制中引入相对位置信息。但这些方法通常需要修改自注意力机制的架构,并且在实现上较为复杂。 -
进行多头注意力机制处理:首先介绍普通的transformer的单头注意力机制。
首先,和之前所述的attention机制一样(此处我们的注意力计算函数设定为点乘方式
然后,为了防止点积过大导致的梯度爆炸,我们对scores进行缩放处理,并且进行softmax归一化,得到注意力权重:
最后,加权求和,我们引入v,将注意力权重乘以各个词向量的值,得到每个词的上下文向量:
而多头注意力机制本质上是对矩阵的一种“拆分”,比如,将一个长为1024的向量拆分为4个长为256的矩阵。
举例:
原来对于KQV,我们得到(为了简化假设KQV都一样):这里的矩阵是2 * 4的矩阵,表示有2个词,每个词向量长度为4。
那么我们将其拆分为4个2 * 1的矩阵:然后分别计算4个注意力分数,和前面所示的单头注意力机制一样,最后再把得到的4个输 出矩阵按照词向量维度方向拼接起来,得到多头拼接的输出矩阵,最后再通过一个线性层 进行最终的整合,得到最终的输出。
为什么要用多头注意力机制?
这4个矩阵原来因为softmax会被归一化,互相产生牵绊因而发挥相近的作用,对于语义理解来说,只是参数量增多,可以承载的信息更加丰富,但是本质上还是处理同种信息。但是,拆分之后,我们对每个矩阵的kqv进行不同的线性变换(也就是乘以不同的权重矩阵),同时归一化是互不干扰,这样就可以让每个矩阵学习到不同类型的信息,从而提升模型整体对于语义的理解能力。我们认为:每个“头”都独立地执行一次单头注意力,关注输入序列中的不同子空间信息。例如,在一个句子中,一个头可能专注于捕捉语法关系(主谓宾),而另一个头可能专注于捕捉语义关系(同义词、反义词)。 -
残差连接和层归一化(residual + layer normalization)
在多层神经网络训练当中,层数一多,极容易出现梯度消失和梯度爆炸的问题(训练不稳定),导致模型无法收敛。因而我们想出了残差连接和层归一化两种方法来缓解这个问题。
残差连接:就是将每一层的输入直接加到输出上:
→
看似简单,但是却极大地缓解了梯度消失的问题。一是由于主流激活函数比如(梯度在0 ~ 1/4),ReLU(梯度在0 ~ 1)等,都会导致梯度在多层网络中不断缩小趋向0,而残差连接直接将输入x加到输出上,使得梯度至少维持在1左右,从而缓解了梯度消失的问题。
二通过降低学习恒等映射难度解决了神经网络的退化。没有残差的时候,我们发现随着层数增多,模型能力不增反降(称为模型退化),按理说,至少可以学习恒等映射使得模型性能不变。这种现象说明了原有神经网络在学习恒等映射是出现了困难(分析:,由于非线性激活函数,实际上学习到一个恒等映射非常困难,参数变化极复杂)。但是,通过残差连接,习得恒等变换则变成了习得。相对于学习恒等变换,学习就要简单多了(L2正则化和优化器以及神经网络本身的梯度下降特性就本身具有趋向0的特性)。于是,残差连接在一定程度上简化了恒等映射的学习难度,使得模型的层数和规模可以更大,从而提升了模型的表达能力。
或者我们有另一种理解:这种的形式本质上是单独抽离出来了,也就是让我们的模型去关注和的差异,而不是本身。这样,模型就可以更专注于学习输入和输出之间的变化,而不是试图重新学习输入本身,从而提升了学习效率和效果。
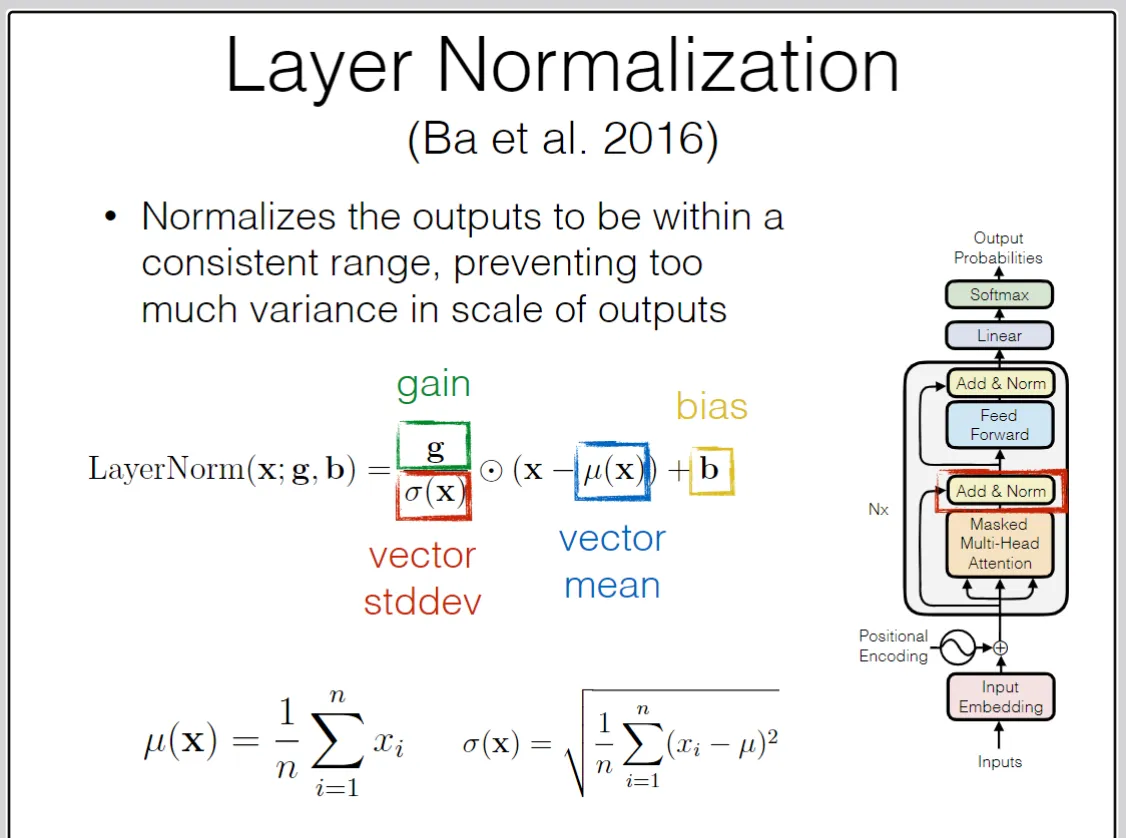
层归一化:归一化家族中的一员。不得不放上经典的图:
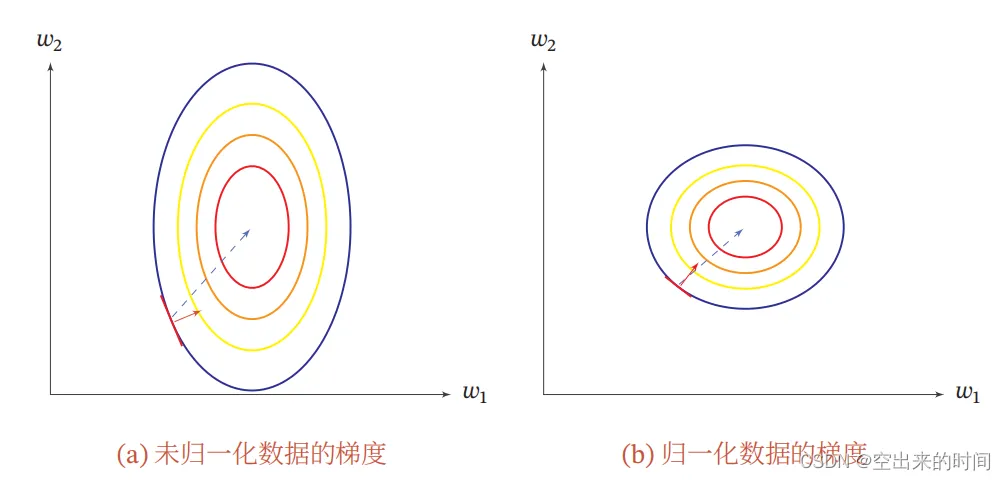
归一化之后让数据变为均值为0,方差为1的分布,从而让数据分布更加稳定,防止梯度爆炸和梯度消失的问题(数据不会过大也不会过小)。同时分布更加均匀,避免了在梯度方向来回震荡但是收敛很慢的情况,就像上图所示,便于梯度迅速下降收敛。
方差均值的归一化处理过于常见不在赘述,额外说明一下是什么:
是一个可训练的参数(不要误解为是函数符号),和b(bias)一样。因为归一化多少会对原来的网络产生影响,有些时候,模型的最佳性能可能需要某些特征具有更大的或更小的幅度,而不是简单地将所有特征都归一化到相同的尺度,于是我们在前面加上一个参数作为系数,来调整特征向量的幅度。
这就像是,虽然所有人都穿上了同样的制服,但 g 和 b 给了他们可以自主选择的配件(b负责偏置,g负责幅度)。网络可以根据需要,为某些层学习一个大增益,为另一些层学习一个大偏置,从而重新获得强大的表达能力。
通过学习,模型可以根据任务需求动态地调整每个特征的幅度,从而提升模型的表达能力和适应性。
具体来说,层归一化是对每一个样本的所有特征进行归一化处理,而不是对一个batch中的所有样本进行归一化处理(和batch normalization区别)。
同样,凡是这种数学方法就有变式和改进:RMSNorm等
其他原理类似不再赘述
补充:layer norm的位置:
最早论文中是进行后置,但是前后置有差别 前置与后置:前置可以在残差连接之前,使得输入向量进行归一化处理,防止输入过大或过小影响后续计 算,同时也让残差连接的输入更加稳定,有助于梯度的传递和模型的收敛。
后置虽然难以防止梯度更新中的不稳定,但是可以保留更多的原始信息,避免过度归一化导致的信息损失, 从而提升模型的表达能力。
5.最后再进行经典的线性层和softmax处理,输出。
其中的线性层是一个2层的全连接层,也是经典的机器学习MLP
4.2.2 tricks to conduct rally training(many dirty works)#
以下都是技巧,简介即可,了解详细看论文去 :),有些甚至自成领域,简单也讲不完
1.Optimization Tricks:SGD,adam,adamW,etc
2.低精度训练:节省计算资源,提升计算效率,之后也会涉及到
3.检查点设置(Checkpoint/Restarts):监控训练过程,以便出了问题可以回去)
4.掩码和填充(序列模型的mini-batch):序列模型的数据原本是不好进行批处理的,因为比如语句,长度不一,于是我们会将短的句子进行填充(padding)成和最长句子一样长,然后进行批处理。而填充的东西我们又不希望他参与注意力计算,于是我们会对填充的部分进行掩码处理(masking),让他在注意力计算中不起作用。
5.截断式反向传播:把长序列分割成小段进行训练(比如按句子分段),分段进行反向传播,不改变正向传播,防止梯度爆炸和梯度消失,而且提升效率,缺点是无法捕捉长距离依赖
4.2.3 比较与优化#
我们之前讨论的每一个步骤都有着优化和进步的空间:

通过这些修改,模型性能有了显著提升
5.Gerneration algorithms#
生成算法,在这里,其实我们主要讲的是解码算法(decoding algorithms),也就是在我们已经有了一个训练好的语言模型之后,如何通过这个模型来生成文本。
首先我们明确,所有这些看似复杂的语言模型其实归根结底都是概率模型,我们通过计算每个词在给定上下文的条件概率来生成文本。
而我们即便已经得到了这个概率分布,如何进行具体的文本生成,这个问题也大有研究余地。
5.1 confidence(置信度)#
置信度描绘了一个词语生成的可信度(下判断认为这个词就是我们想选择的词的可靠程度),虽然对于不同概率分布,对于都是概率最大的词,但是例如:第一个可能词汇概率为99%,之后可能词汇概率总共1% 和 第一个词概率为50%,第二个词30%,第三个词10%,剩下的10% ,这两种情况,显然前者的置信度更高。
置信度往往和Calibration(校准)有关,校准的目的是使得模型输出的概率更接近真实的概率分布。通过对模型的输出进行后处理,可以提高置信度的可靠性,从而提升生成文本的质量。
5.2 hallucination(幻觉)#
在当下的大预言模型时代,幻觉这个词被经常提及,指的是模型生成了不符合事实或编造的信息。需要强调,幻觉是难以避免的,即使所有的预训练数据都是真实的,这种情况也是成立的!
例如:即便在所有的输入中,都给与的是“2+2=4”的信息,在进行输出时,模型的概率分布中例如“2+2=5”,“2+2=8”等等依然会被分配非0的概率,依然有可能会被生成。
于是,如何采样(sample),如何对对概率分布本身进行处理,如何从众多概率输出中找到最合适的答案成为重要问题。
5.3 Ancestral Sampling(祖先采样)#
Ancestral Sampling是最简单的采样方法,直接从概率分布中采样,被采样到的可能性与其在概率分布中的值正相关。
然而,这种方法会遇到严重问题:长尾问题(long tail problem)。
例如:第一个词的概率为30%,第二个词20%,第三个词10%,剩下的40%分布在1000个词上,每个词大概只有0.04%的概率,那么我们就会发现,模型有很大概率选取到后面的1000个词,但我们可以轻易发现,对于1000个词中的任何一个词,其实都是比较差的选择结果。
那么如何克服这个问题呢?
5.4 Top-k/Top-p/Epsilon sampling#
Top-k sampling是对Ancestral Sampling的改进,直接将概率分布中概率值排名前k的词语作为候选词,然后从中进行采样。
Top-p sampling(也称为nucleus sampling)是另一种改进方法,它不是固定选择前k个词,而是选择累计概率达到p的最小词集,然后从中进行采样。
Epsilon sampling是Top-p sampling的一个变种,它选择所有概率大于某个阈值ε的词语作为候选词,然后从中进行采样。
总之核心是忽略长尾中的无效词,提升采样质量。
5.5 temperature(温度)#
温度是控制采样多样性和确定性的一个参数,直接操控概率分布本身。(经常在云平台调用模型api的时候看到)
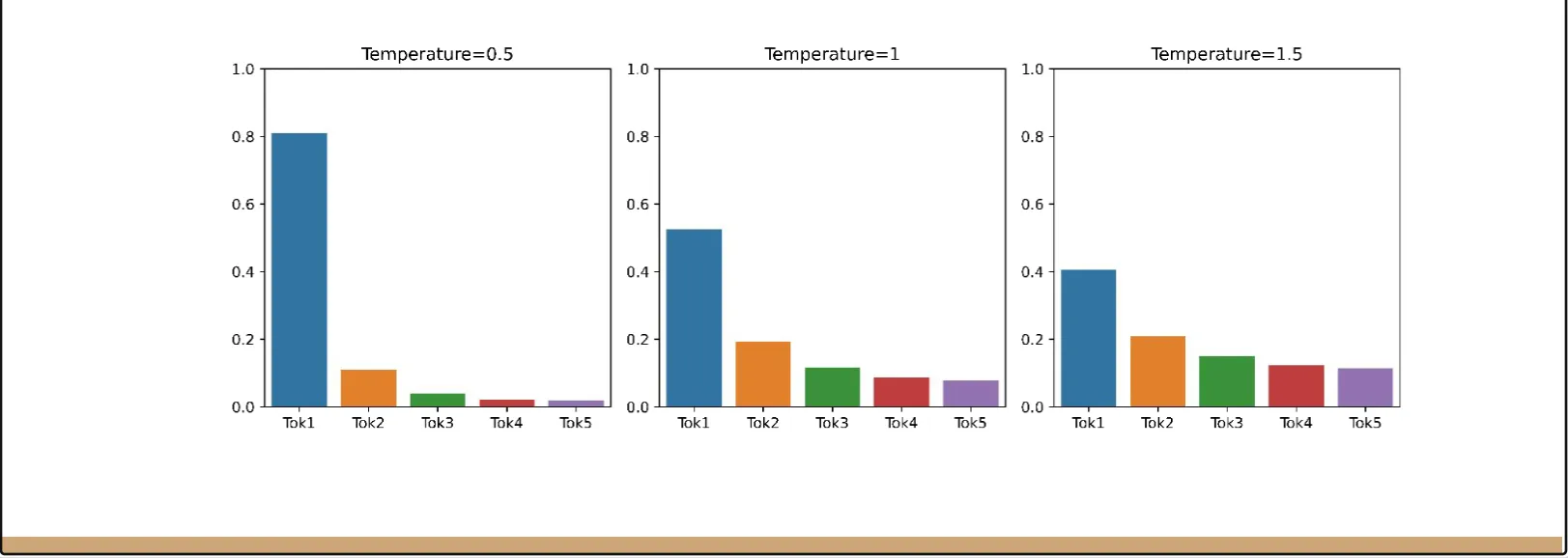
温度用来调整模型的概率分布,不会影响模型概率分布中各个词概率大小关系,但是会影响概率分布的平滑程度。如图。
温度越高,采样越多样化,模型生成的文本可能更加丰富和多样,但也可能包含更多不相关或不合适的内容。当我们倾向于生成更具创造性的文本时,可以适当提高温度。而当我们希望生成更为准确和一致的文本时,则可以降低温度。
5.6 Contrastive decoding(对比解码)#
我们现在有两个模型,一个是能力强的专家模型,一个是能力弱的业余模型。我们可以利用两者更加充分的发掘专家模型的能力:
专家,他对一个决定非常确信;而业余者对这个决定不太确定,那么专家的意见就更有价值,这个决定就是可以体现专家独特价值的,更好的决定。
于是我们通过给两个模型同样的输入,得到两者的概率分布,然后我们将专家模型的概率分布减去业余模型的概率分布(相同词概率相减),得到一个新的概率分布,然后再进行上述的采样。
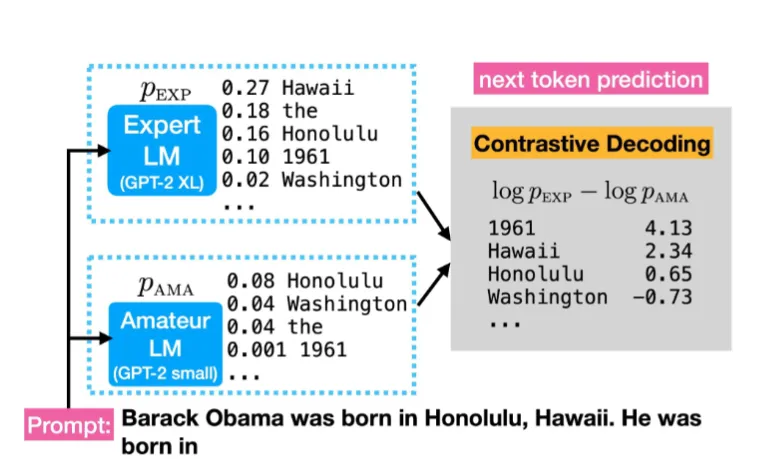
通过这种对比,对比解码能够过滤掉那些两个模型都容易猜到的、不具创造性或不准确的词语,从而优先选择那些只有更强大的专家模型才能准确预测的词语。
这使得它能生成更准确、更具体、更具事实性的文本,同时还能有效减少幻觉的产生。它利用了“专家模型”的强大知识,同时通过“业余模型”来“排除干扰”,找到真正有价值的预测。
5.7 mode-seeking search(模式寻优搜索)#
前面涉及的sampleing方法还是为了找到一个更加精确合理的概率分布,使得我们的可选项更优,祖先采样的随机性也比较强。但是,很多情况下,我们期望得到一个精确的最佳输出结果。
5.7.1 greedy search(贪心搜索)#
很自然的,我们想到贪心搜索,谁概率大就选谁。但是往往有问题:从一个词的最优角度,贪心是好的,但是从一个长序列,也就是总体句子的角度,前面词的概率高,不等于后面词在概率分布中也高,并不能保证整体最优。
5.7.2 beam search(束搜索)#
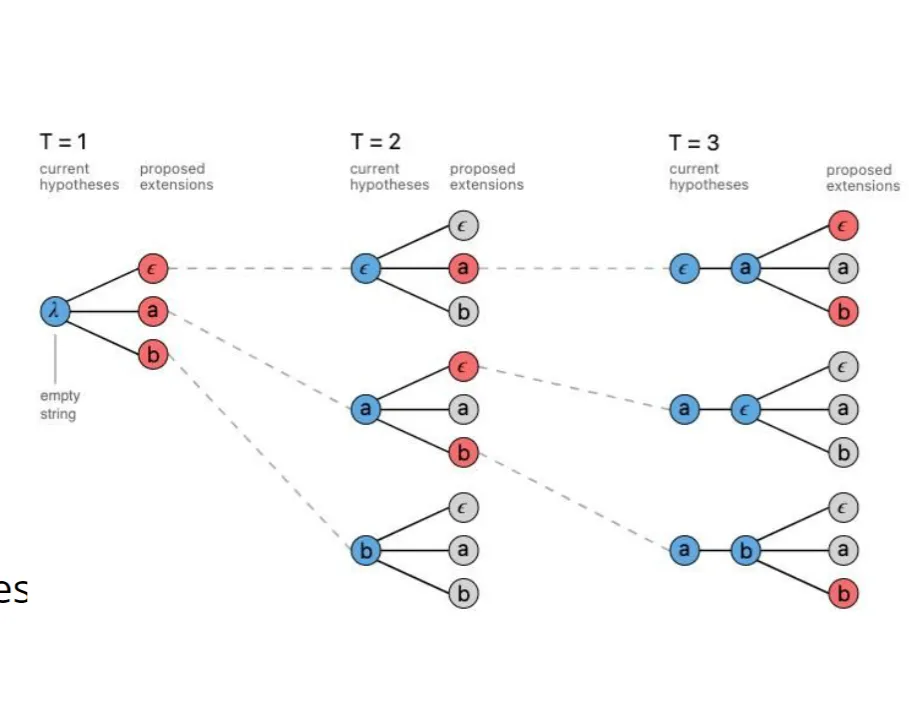 类似于搜索策略对贪心算法的改进,我们利用这种类似广度搜索的策略来找到整体意义上的最优句子生成策略。
类似于搜索策略对贪心算法的改进,我们利用这种类似广度搜索的策略来找到整体意义上的最优句子生成策略。
具体来说,束搜索会在每一步生成多个候选词(而不是只选择概率最高的词),然后每个候选词再继续衍生出新的分支,不断进行形成搜索的树状结构。
而有了候选词,我们的操作余地就更大了,我们可以选择不同的策略来选择候选词:
0.常规的采样法,我们尽可能找到更加可能的词作为候选词
但同时,也要考虑多样性
1.候选词很多情况下会是近义词,这样不利于语句的多样性,我们可以通过近义词判断来修改相同含义的词被选入候选词的权重分数,从而减少近义词的出现,提升其他词的出现概率。
2.可以进行一定程度上的随机采样,使得不是概率得分最大的词也可能被选上
5.8 Minimum Bayes risk(最小贝叶斯风险)#
前面我们的选择逻辑都是基于概率分布的最大化,但是我们没有考虑风险(risk)。
我们知道,我们生成的句子最后的评判要求还是以实际内容为核心。
例如,根据束搜索,我们得到了这样几个概率最高的句子:
0.3 The cat sat down.
0.15 The cat got out of there.
0.2 The cat sprinted off.
0.25 The cat ran away.
0.1 other sentences.
我们发现虽然第一句话在概率分布中最高,但是后三句话表达的基本是同一个意思(猫跑掉了),而他们的概率加起来已经远远超过了第一句话的概率,于是我们认为,综合来看,猫跑掉了这个意思才是最有可能的。
于是我们认为,第一句话虽然看似概率大,但是风险也很大,后几个句子的风险相对小的多,我们希望的是综合考虑得到高概率同时也低风险的选择
于是,我们引入Minimum Bayes Risk (MBR,最小贝叶斯风险)
其中,是候选句子集合,是参考句子集合,是一个评估函数,用来衡量候选句子与参考句子之间的相似度。
首先,使用采样方法(如祖先采样或 Top-p 采样)生成一系列可能的输出序列,构成一个候选集,其中的每一个元素(也就是一个可能的输出句子),我们称为候选输出 y ′ ∈。
然后,定义风险,为每个候选输出 y‘计算其与候选集中所有其他候选输出的平均不相似度,也就是所谓“风险”。
最后,选择那个使得风险最低的输出 y′作为最终答案。
5.8.1 MBR的变体:输出集成(Output Ensembling)#
针对于多个模型的情况,我们在构建候选集的时候,原来是同个模型的多种输出,现在可以是多个模型的输出。比较不同模型输出结果的风险。如果一个输出与来自不同模型的许多其他输出都非常相似,那么它就更有可能是“正确”或“稳健”的(类比投票)
5.8.2 MBR的变体:自洽(self-consistency)#
引入思维链(CoT),多次采样,提取最终的频繁答案。(之后涉及CoT再细讲)
5.9 constrained generation(约束生成)#
如果我们被要求有一些内容在生成过程中必须出现,或者有一些内容绝对不能出现,我们该怎么办?
只在input中注明是不够的(比如在prompt中说不要出现xxx),根据前面有关幻觉的论述,我们知道模型有可能会忽略这些指令,尤其是当这些指令与训练数据中的模式相冲突时。
最简单的思路:在生成分布的时候,检测到相关的禁止词语,就把他的得分设为0,以避免选择它作为输出。
弊端:
1.有近义词还是处理不了,本质上输出同样意思的句子
2.前面的内容已经生成好的,那个禁止的词反而是在这个语境下最佳的词,如果强行避免反而让句子完全不对头。
例子:假设你禁止了 “climbing” 这个词。模型生成了这样一句话的前半部分:“The mountain was steep, and he began his …”。 在这个上下文中,最自然、概率最高的词就是 “climbing” 或 “ascent”。 由于你把 “climbing” 的概率设为0,模型只能退而求其次,选择一个概率次高的词。它可能会选择一个不那么贴切的词,比如 “journey”(旅程)或者 “walk”(行走),导致句子变得不自然 (“he began his walk”),甚至可能会为了回避而生成更奇怪的组合。
3.一词多义,有可能这个词其实在语境中作为另一个意思应当出现,但是现在一股脑扼杀了
另一种思路:多次进行输出得到多个序列
缺点:太慢啦!可能好多都达不到要求
FUDGE思路:先用一个正常模型输出概率分布,然后用另外一个专门训练用识别约束的模型来分别判断以上的输出结果作为语句,其语义对于约束来说的符合程度并相应打分,然后将这个分数和原来模型的概率分布进行结合,得到一个新的概率分布,然后再从中采样。相当于让另一个模型作为监管者。
RLHF:先跳过,之后详述
Reward-augmented decoding(奖励增强解码):对于每一个输出的词的概率分布,整合前面已经生成的部分,分别用一个奖励模型给每个未完成的句子打分,估算出一个未来的奖励分数。系统会根据这个 “原始概率 + 未来奖励” 的综合分数来决定最终选择哪个词作为下一个词。
5.10 实际考量#
在实际考量时,我们往往会考虑速度和计算效能等因素,因而出现了很多工程上的tricks
5.10.1 speculative decoding(推测解码)#
还是前面提到的专家模型和业余模型,
业余模型速度快但准确性差,专家模型相反。我们可以用业余模型来快速生成候选词,然后用专家模型来对这些候选词进行重新打分,从而选择最优的词作为输出。
这样做的好处是,业余模型通常计算速度更快,可以迅速生成多个候选词,而专家模型则可以更准确地评估这些候选词的质量。通过这种方式,我们可以在保证输出质量的同时,大幅提升生成速度。
具体流程与原理:
- 并行起草 (Drafting):
草稿模型 基于当前已确认的文本,快速地、自回归地生成一小段候选序列(比如 个 token)。
这个过程非常快,因为 是一个小模型。
- 一次性验证 (Verification):
目标模型 将“已确认的文本 + 整个草稿序列”作为输入,进行一次前向传播(forward pass)。
这次计算是并行的,它会一次性地计算出如果由它自己来写,它会为草稿中的每一个位置选择什么词,以及对应的概率分布。这是最关键的一步,它用一次大模型的计算,换来了对多个 token 的“意见”。
- 逐词对比与接受/拒绝 (Token-by-Token Acceptance):
系统从草稿的第一个词开始,逐一对比草稿模型和大模型的“想法”。
对于草稿中的第
i个词:
- 如果草稿模型选择的词,和大模型在该位置上会选择的词一致,那么这个词就被接受 (Accept)。
- 如果不一致,这个词就被拒绝 (Reject),并且对比过程立刻停止。
假设草稿中有
k个词,最终有n个词被连续接受了()。
- 修正并重启 (Correction & Restart):
- 所有
n个被接受的词被追加到最终的输出序列中。- 在第一个被拒绝的位置,系统会根据大模型在“验证”步骤中算出的概率分布,重新采样一个正确的词。
- 然后,流程回到第1步,草稿模型再从这个新的、被修正过的序列开始,生成下一段草稿。
为什么这样会更快?#
LLM推理的主要瓶颈在于内存带宽——每次生成一个token,都需要从显存中加载整个庞大的模型权重。
- 在传统解码中,生成5个token需要5次这样缓慢的加载和计算过程。
- 在推测解码中,如果运气好(草稿模型预测得准),我们可能只需要1次大模型的加载和计算,就能确认4-5个token。即使运气不好,只确认了1-2个,也通常比传统方法快。
最终的加速比取决于草稿的接受率,也就是小学徒的“猜对率”。只要学徒不是胡乱猜测,这个方法就能带来显著的速度提升。
5.10.2 attention sinks(注意力下沉)#
在此之前,先介绍KV cache(键值缓存)
这是 Transformer 模型(也就是所有现代大语言模型的基础)在进行推理(Inference)时,一个极其重要的性能优化技术。可以说,没有 KV Cache,现在的大模型对话应用基本无法实现。
核心思想:不要重复计算已经算过的内容(类似用空间换时间的思想)#
1. 背景:没有 KV Cache 会发生什么?#
首先,我们需要简单回顾一下 Transformer 的自注意力(Self-Attention)机制。在生成文本时,模型是 自回归(Autoregressive) 的,即一个词一个词地往外蹦。
- 当模型要生成第 1 个词时,它会基于输入计算出这个词的 Query (Q¹), Key (K¹), Value (V¹) 向量。
- 当模型要生成第 2 个词时,它需要看前面的词。它会基于第 1 个词和第 2 个词的输入,计算出 (K¹, V¹) 和 (K², V²)。请注意,(K¹, V¹) 被重新计算了一遍!
- 当模型要生成第 100 个词时,为了计算注意力,它需要前面所有 99 个词的 Key 和 Value。于是,它会把前 99 个词的 (K¹, V¹), (K², V²), …, (K⁹⁹, V⁹⁹) 全部重新计算一遍。
问题显而易见:每生成一个新的词,都要把前面所有词的 Key 和 Value 重新算一遍,这是巨大的、完全不必要的计算浪费。计算量会随着序列长度的增加而呈二次方增长,速度会变得极慢。
2. 解决方案:KV Cache 如何工作?#
KV Cache 的思想非常简单:算过一次的 Key 和 Value,就存起来,下次直接用。
我们再来看一下启用 KV Cache 后的流程:
- 处理输入 (Prompt):
模型接收到你的初始输入(比如 “从前有座山”)。
它会一次性计算出输入中每个词的 Key 和 Value 向量,并将它们存入一个专用的内存空间(通常是 GPU 显存),这个空间就是 KV Cache。
Cache 内容:
[K_从, V_从; K_前, V_前; K_有, V_有; ...]
- 生成第 1 个新词 (比如 “山”):
模型只需要为当前这个新词 “山” 计算出它自己的 Query (Q_山), Key (K_山), Value (V_山)。
然后,它将新的 (K_山, V_山) 追加到 KV Cache 的末尾。
在计算注意力时,Q_山 会和 Cache 中所有的 Key(包括之前输入的和它自己的)进行计算。
Cache 内容更新为:
[...; K_山, V_山]
- 生成第 2 个新词 (比如 “里”):
- 模型不再需要重新计算 “从前有座山” 的 K 和 V。
- 它只需要为新词 “里” 计算出 (Q_里, K_里, V_里)。
- 将 (K_里, V_里) 再次追加到 KV Cache 中。
- Q_里 会和 Cache 中不断增长的 K 向量进行计算。
通过这种方式,每次生成新词时,昂贵的 K 和 V 向量生成操作都只针对当前这一个新词进行,而之前的所有 K 和 V 都直接从缓存中读取。这将原本的二次方计算复杂度降低到了线性复杂度,带来了数量级的速度提升。
3. KV Cache 的重要性和代价#
- 重要性: KV Cache 是实现大模型流畅对话、代码补全等应用的基础,没有它,推理速度会慢到无法接受。
- 代价: 占用大量显存。Cache 中需要存储模型每一层、每一个注意力头的 K 和 V 向量。当上下文窗口(Context Window)很长时(比如 32k, 128k),KV Cache 会占用巨量的显存,这往往是限制模型能处理的最大上下文长度的主要瓶颈。
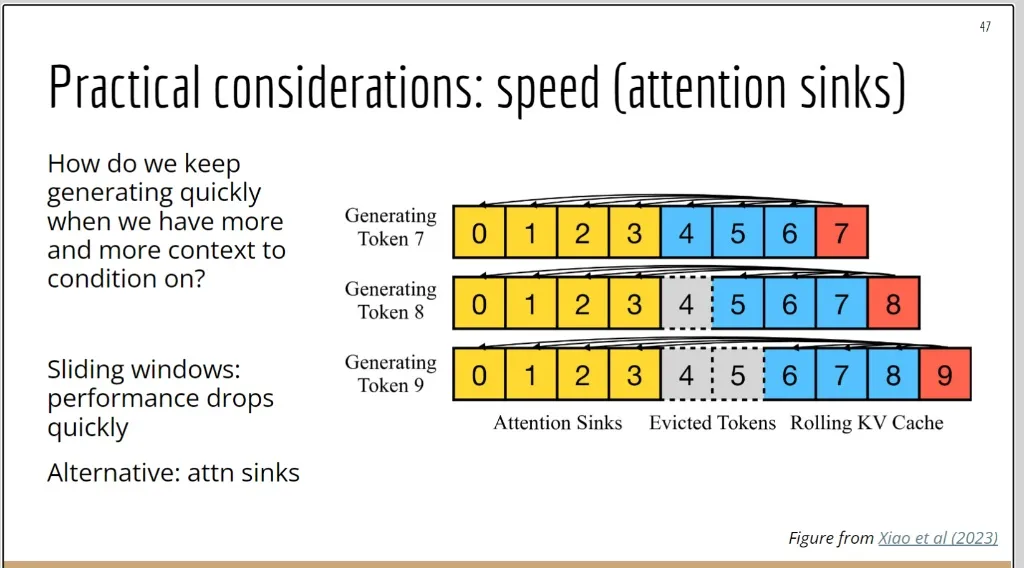
在了解了KV cache后,我们可以进一步了解 “注意力下沉”(Attention Sinks) 技术。
他的作用是:在处理长文本时发挥作用,通过 忽略 某些东西,提升模型处理长序列时的速度
让我们一步步来解析:
1. 问题背景:为什么长文本生成会变慢?#
- 大语言模型(如GPT系列)的核心是Transformer架构,其关键是自注意力(Self-Attention)机制。
- 在生成每一个新词时,这个新词需要与之前所有的词进行计算,来决定“关注”哪些内容。
- 这意味着,上下文序列越长,生成下一个词所需的计算量就越大(呈二次方增长)。这导致在处理长文档或进行长对话时,模型的响应速度会急剧下降。
2. 常规解决方案及其缺陷:滑动窗口 (Sliding Windows)#
- 一个直观的解决方法是滑动窗口:不让模型看全部的上下文,只看最近的一部分(比如最近的4096个词)。
- 缺陷: 幻灯片中明确指出 “performance drops quickly”(性能急剧下降)。这是因为,如果把对话或文章开头的关键信息(比如“你是一个诗人,请用五言绝句回答”)移出了窗口,模型就会“忘记”这个指令,导致回答质量崩盘。
3. 新的解决方案:注意力下沉 (Attention Sinks)(又称注意力汇点)#
这张图的核心就是解释 “attn sinks” 是如何工作的。研究者(Xiao et al. 2023)发现一个有趣的现象:
- 即使文章开头的几个词(token)在语义上不那么重要(比如”The”, “A”等),Transformer模型在预训练过程中已经习惯了把大量的注意力“存放”在这些初始位置上。
- 这些初始token就像一个 “注意力汇点”或“锚点” ,帮助模型稳定地分配后续的注意力。如果粗暴地把它们丢掉(像滑动窗口那样),模型的注意力分配机制就会“崩溃”,导致性能下降。
4. 图示详解:结合“注意力汇点”和“滑动窗口”#
这张图展示了一种两全其美的策略:
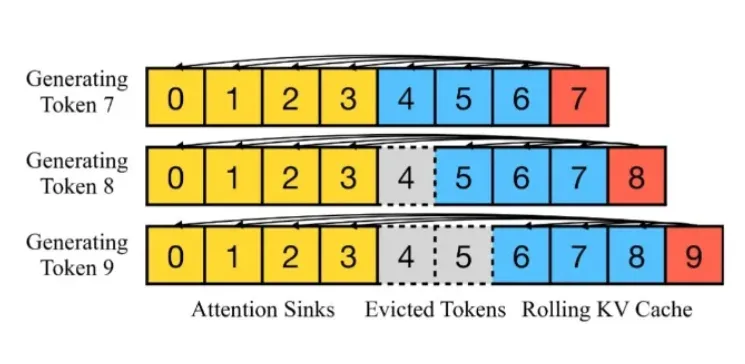
-
黄色部分 (Attention Sinks): 代表序列最开始的几个token(0, 1, 2, 3)。无论上下文变得多长,这部分内容永远被保留在缓存中。 它们就是那个起稳定作用的“锚点”。
-
蓝色部分 (Rolling KV Cache): 代表最近的几个token。这部分像一个滑动的窗口,保留了最新的上下文信息。
-
灰色虚线部分 (Evicted Tokens): 代表中间的token。当序列太长,需要腾出空间时,这些处于中间位置的token会被丢弃(evict)。
我们来看生成 Token 9 的过程:
- 此时的上下文已经有了0到8共9个token。
- 为了控制计算量,系统需要丢弃一个旧的token。它选择丢弃中间的 Token 4。
- 在生成 Token 9 时,它的注意力会计算:
- 与黄色部分(Attention Sinks, 0-3) 的关联。
- 与蓝色部分(Rolling KV Cache, 5-8) 的关联。
- 它不会与被丢弃的Token 4进行计算。
总结来看,“注意力汇点” (Attention Sinks) 技术的核心思想是:
在必须缩减上下文长度以保证速度时,不能简单地只保留最近的文本。我们必须永久保留开头的几个token作为“锚点”,然后再结合一个保留最新文本的滑动窗口。
通过这种方式,既通过丢弃中间token节省了大量的计算和显存,又通过保留“注意力汇点”避免了模型性能的急剧下降,实现了速度和效果的兼得。这是当前很多长文本(Streaming LLM)应用中的关键技术。
5.11 总结#
总结起来,其实解码模型在本节合计就是两种思路:
第一种,在每一步解码中选择一个合适的函数方法来操控概率分布。
第二种:在整个解码步骤中(也就是等一定长度序列已经生成后),再用另一个函数或者模型对于已经生成的序列进行选择或者修改。